اگر وارد دنیای پردازش زبان طبیعی شدهاید و میخواهید با یک کتابخانه فارسی و گرافمحور کار کنید، Rakhshai Graph-based NLP میتواند نقطه شروع خوبی باشد. این کتابخانه برای تبدیل متنهای فارسی به ساختارهای گرافی طراحی شده و در کارهایی مثل خلاصهسازی متن، طبقهبندی متن، توصیهگر محتوا و تحلیل شبکههای اجتماعی کاربرد دارد.
در این مقاله، فقط روی بخش راهاندازی سریع تمرکز میکنیم؛ یعنی نصب پروژه، فعالسازی محیط، اجرای تستها و اجرای یک نمونه ساده خلاصهسازی.
پیشنیازها
قبل از نصب، بهتر است این موارد را روی سیستم داشته باشید:
- Python نسخه 3.9 یا جدیدتر
- Git برای دریافت پروژه از GitHub
- pip برای نصب پکیجهای پایتون
- اینترنت پایدار برای دانلود وابستگیها
برای سختافزار هم اگر فقط میخواهید نصب کنید و مثالهای کوچک را اجرا کنید، یک سیستم معمولی کافی است. کارت گرافیک الزامی نیست، چون در صورت نبود GPU میتوان پروژه را با CPU اجرا کرد.
| کاربرد | سختافزار مناسب |
|---|---|
| نصب، تست، دموهای کوچک | 4GB RAM، CPU معمولی |
| کار پژوهشی سبک با چند هزار سند | 8GB تا 16GB RAM |
| گراف متنی بزرگ / دهها هزار سند | 32GB RAM یا بیشتر |
| آموزش GCN/GraphSAGE سریعتر | GPU انویدیا با حداقل 4GB تا 8GB VRAM، ولی اجباری نیست |
مرحله اول: دریافت پروژه از GitHub
ابتدا یک پوشه مناسب برای پروژههای پایتونی خود انتخاب کنید. سپس ترمینال یا Command Prompt را باز کنید و دستور زیر را اجرا کنید:
git clone https://github.com/bazpardazesh-org/Rakhshai-Graph-based-NLP.gitبعد وارد پوشه پروژه شوید:
cd Rakhshai-Graph-based-NLPحالا شما کد پروژه را روی سیستم خود دارید.
مرحله دوم: ساخت محیط مجازی پایتون
برای ساخت محیط مجازی بنویسید:
python -m venv .venvحالا باید این محیط را فعال کنید.
در ویندوز PowerShell:
.venv\Scripts\Activate.ps1در ویندوز CMD:
.venv\Scripts\activate.batدر macOS یا Linux:
source .venv/bin/activateوقتی محیط فعال شود، معمولاً ابتدای خط ترمینال شما چیزی شبیه این دیده میشود:
(.venv)مرحله سوم: نصب کتابخانه
حالا به مرحله اصلی میرسیم. در بخش راهاندازی سریع پروژه، برای نصب از این دستورها استفاده شده است:
python -m pip install -e .این دستور، هسته اصلی کتابخانه را نصب میکند.
اما برای استفاده از قابلیتهایی مثل یادگیری ماشین، خلاصهسازی مبتنی بر TextRank، توصیهگر محتوا و محاسبات TF-IDF، بهتر است نسخه دارای وابستگیهای یادگیری ماشین را هم نصب کنید:
python -m pip install -e ".[ml]"در README توضیح داده شده که بعضی قابلیتها مثل build_document_graph، recommend_similar و textrank_summarise به scikit-learn وابستهاند و این وابستگی با گزینه ml نصب میشود.
پس برای نصب راحتتر پیشنهاد ما این است که از همان ابتدا این دو دستور را پشت سر هم اجرا کنند:
python -m pip install -e .
python -m pip install -e ".[ml]"مرحله چهارم: بررسی نصب با اجرای تستها
بعد از نصب، بهتر است مطمئن شوید همه چیز درست نصب شده است. برای این کار ابتدا pytest را نصب کنید:
python -m pip install pytestسپس تستهای پروژه را اجرا کنید:
python -m pytestاگر تستها بدون خطای جدی اجرا شدند، نصب شما موفق بوده است.
مرحله پنجم: اجرای یک نمونه ساده خلاصهسازی فارسی
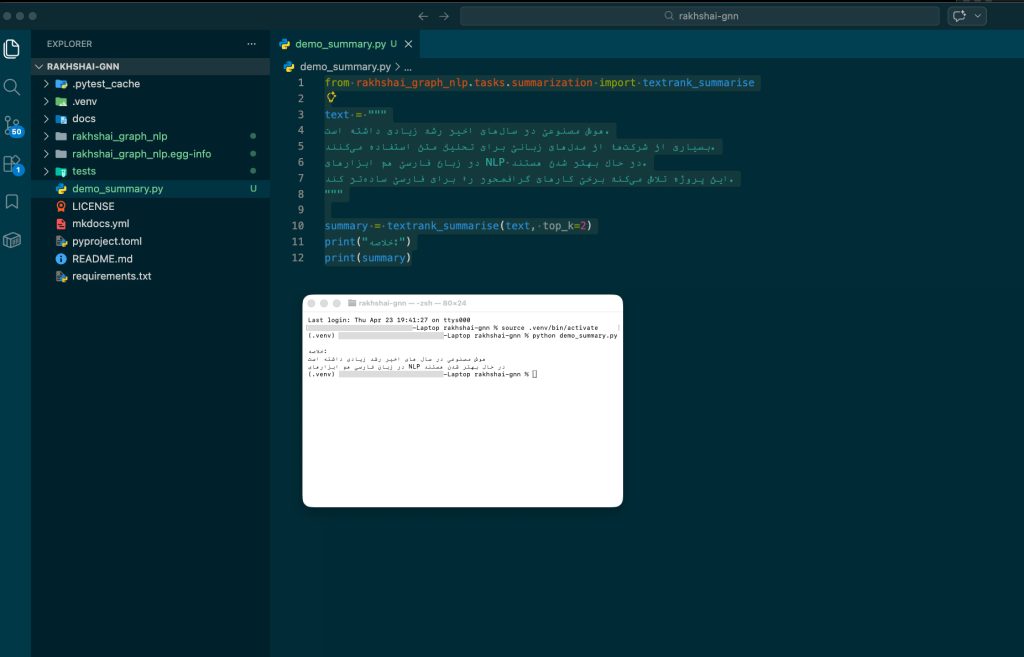
حالا یک مثال ساده اجرا میکنیم تا ببینیم کتابخانه واقعاً کار میکند یا نه.
در پوشه اصلی پروژه، یک فایل جدید با نام زیر بسازید:
demo_summary.pyداخل این فایل، کد زیر را قرار دهید:
from rakhshai_graph_nlp.tasks.summarization import textrank_summarise
text = """
هوش مصنوعی در سالهای اخیر رشد زیادی داشته است.
بسیاری از شرکتها از مدلهای زبانی برای تحلیل متن استفاده میکنند.
در زبان فارسی هم ابزارهای NLP در حال بهتر شدن هستند.
این پروژه تلاش میکند برخی کارهای گرافمحور را برای فارسی سادهتر کند.
"""
summary = textrank_summarise(text, top_k=2)
print("خلاصه:")
print(summary)برای اجرای فایل بنویسید:
python demo_summary.pyاگر همه چیز درست باشد، باید خروجیای شبیه این ببینید:
خلاصه:
هوش مصنوعی در سالهای اخیر رشد زیادی داشته است
در زبان فارسی هم ابزارهای NLP در حال بهتر شدن هستندخروجی دقیق ممکن است بسته به نسخه کتابخانهها یا تغییرات پروژه کمی متفاوت باشد، اما باید یک خلاصه کوتاه از متن فارسی چاپ شود.
مرحله ششم: اجرای آزمایش خط فرمان
این پروژه یک رابط خط فرمان به نام rgnn-cli هم دارد. در README گفته شده که برای اجرای یک آزمایش کوچک با مدل GCN میتوانید از این دستور استفاده کنید:
rgnn-cli --model gcn --device cudaاما اگر کارت گرافیک ندارید یا نیازی نمی بینید ، از CPU استفاده کنید:
rgnn-cli --model gcn --device cpuبرای بیشتر کاربران و نصب راحتتر، اجرای نسخه CPU منطقیتر است، چون نیاز به نصب CUDA و تنظیمات کارت گرافیک ندارد.
خطاهای رایج هنگام نصب
۱. دستور python شناخته نمیشود
در ویندوز ممکن است لازم باشد بهجای python از این دستور استفاده کنید:
pyمثلاً:
py -m pip install -e .۲. خطا هنگام نصب وابستگیهای یادگیری ماشین
اگر هنگام نصب .[ml] خطا گرفتید، اول pip را بهروز کنید:
python -m pip install --upgrade pipسپس دوباره نصب را اجرا کنید:
python -m pip install -e ".[ml]"۳. خطا هنگام اجرای فایل نمونه
مطمئن شوید فایل demo_summary.py را داخل پوشه اصلی پروژه ساختهاید؛ همان جایی که فایلهایی مثل README.md و pyproject.toml وجود دارند.
جمعبندی
برای نصب سریع کتابخانه رخشای روی سیستم شخصی، مسیر کلی این است:
git clone https://github.com/bazpardazesh-org/Rakhshai-Graph-based-NLP.git
cd Rakhshai-Graph-based-NLP
python -m venv .venv
source .venv/bin/activate # macOS/Linux
python -m pip install -e .
python -m pip install -e ".[ml]"
python -m pip install pytest
python -m pytestدر ویندوز، بهجای دستور فعالسازی بالا، از این دستور استفاده کنید:
.venv\Scripts\Activate.ps1بعد از نصب، میتوانید با ساخت فایل demo_summary.py یک نمونه خلاصهسازی فارسی را اجرا کنید و مطمئن شوید کتابخانه بهدرستی کار میکند.
این پروژه برای کسانی مناسب است که میخواهند پردازش زبان فارسی را فقط با روشهای کلاسیک NLP دنبال نکنند و وارد مدلسازی گرافی متن شوند. برای شروع، همین راهاندازی سریع کافی است؛ بعد از آن میتوانید سراغ بخشهای پیشرفتهتر مثل ساخت گراف متن، آموزش GCN و استفاده از GraphSAGE بروید.


